
Machine Learning vs Deep Learning: The Honest Difference. These two terms get used interchangeably and incorrectly all the time. Here is what actually separates them, and when each is the right tool.
If you have spent any time reading about AI, you have probably noticed that machine learning and deep learning are used as if they were the same thing. They are not. The difference matters, especially when you are deciding what to study next.
The Short Version
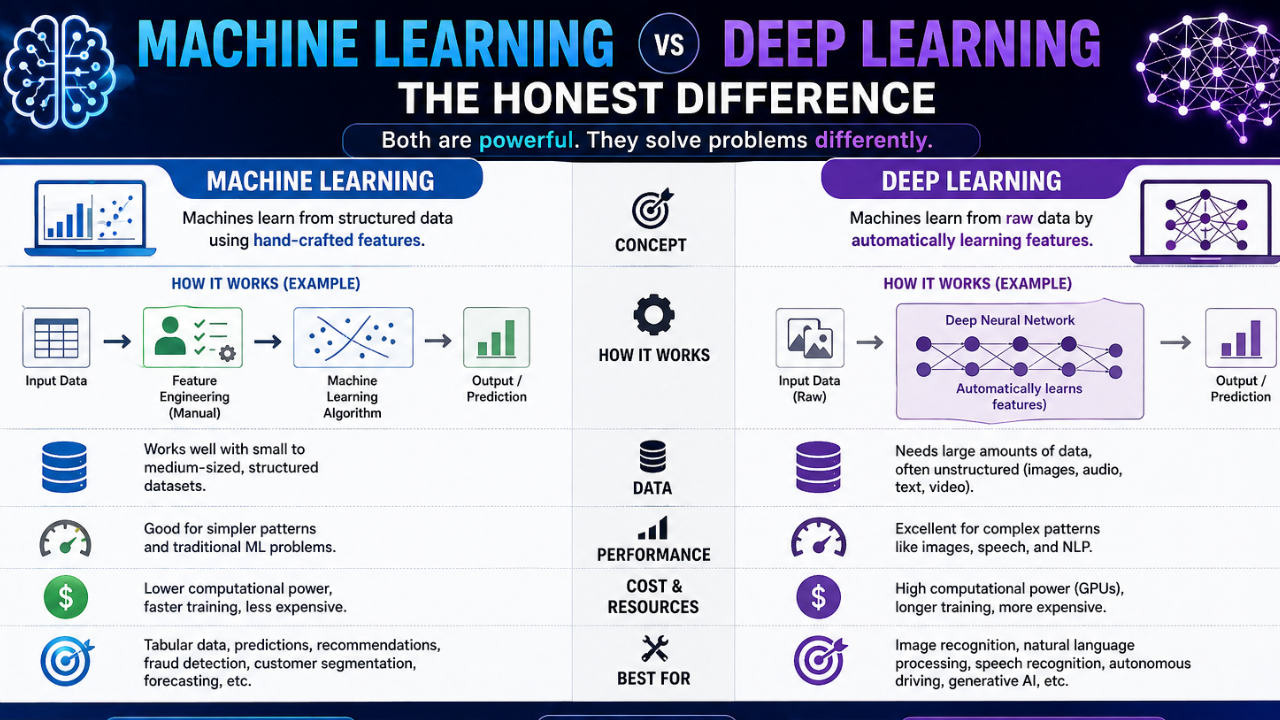
Deep learning is a subset of machine learning. All deep learning is machine learning, but not all machine learning is deep learning. The defining feature of deep learning is the use of neural networks with many layers — typically far more than would have been practical even ten years ago.
Classical Machine Learning
Classical machine learning includes algorithms like linear regression, decision trees, random forests, gradient boosting, and support vector machines. These methods work extremely well on structured tabular data — the kind of spreadsheet-shaped information that powers most real-world business problems.
Three things make classical ML attractive:
- It runs fast on a laptop CPU.
- It is generally more interpretable.
- It often beats deep learning on small datasets.
Deep Learning
Deep learning shines where the input is unstructured: images, audio, free-form text, video. The layered architecture lets the network build up increasingly abstract representations. Early layers in an image model detect edges; later layers detect eyes, faces, and emotions.
The price you pay is data and compute. Deep models typically need thousands or millions of examples and specialised hardware to train.
When to Use Which
A practical rule of thumb that has held up for years:
- Tabular data, fewer than 100,000 rows — start with gradient boosting (XGBoost, LightGBM, or CatBoost). It is faster, cheaper, and usually wins.
- Images, audio, text, or sequential data — start with a pretrained deep model and fine-tune it.
- Tabular data, many millions of rows — both approaches are viable; benchmark them.
The Misconception That Costs Beginners Time
Many newcomers skip classical machine learning entirely because deep learning sounds more impressive. This is a strategic mistake. Most production systems are still gradient-boosted trees on tabular features. Learning sklearn well will make you employable faster than building yet another image classifier.
What to Learn First
- Linear regression, logistic regression, and how to read a confusion matrix.
- Cross-validation and why it matters more than your favourite metric.
- Then, only then, move on to neural networks.
Skipping foundations is the surest way to build models that look good on training data and quietly fail in production.
Follow on Facebook


