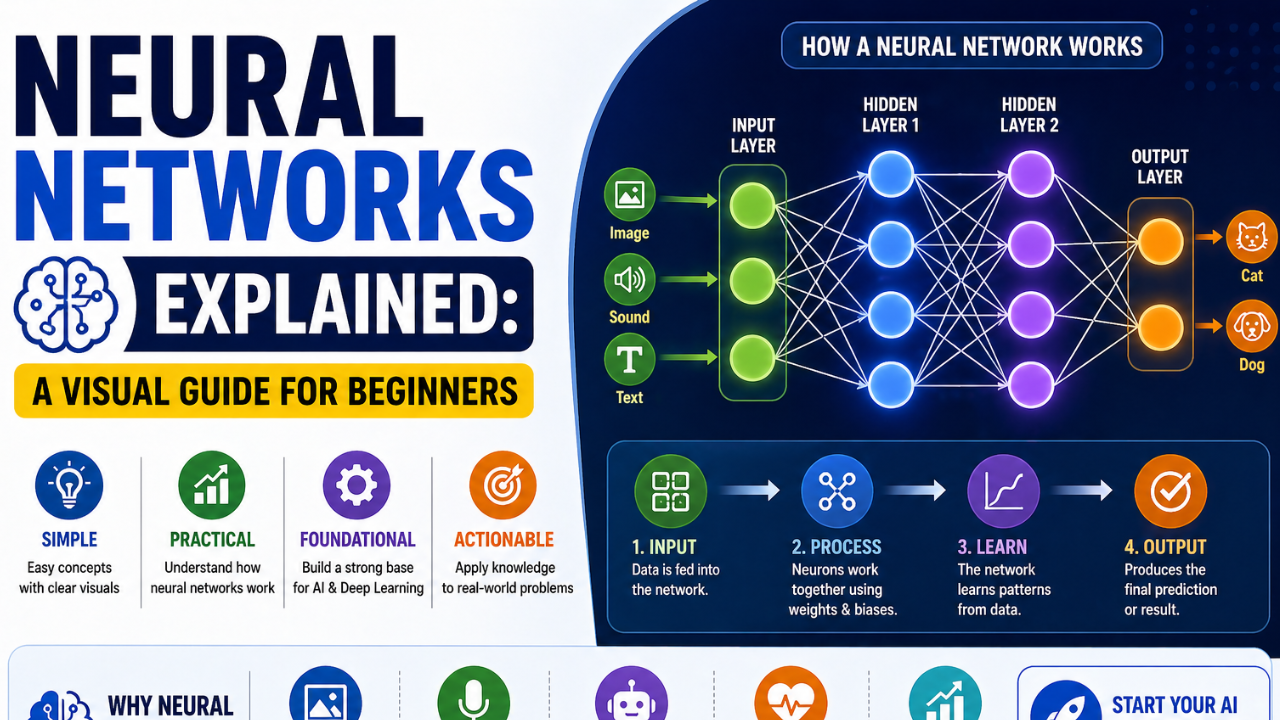
Neural Networks Explained: A Visual Guide for Beginners. Strip away the equations and the marketing. A neural network is a layered system that turns numbers into more useful numbers. Here is how.
Neural networks have an unfortunate reputation for being incomprehensible without years of advanced mathematics. This is mostly false. The basic idea is simple, and you can carry the right mental picture with you for years before you ever need a single formula.
The One-Line Definition
A neural network is a chain of mathematical functions that transforms numbers, layer by layer, into a more useful representation of the input. That is the entire concept. Everything else is detail.
The Building Block: A Single Neuron
A single neuron does three things: it multiplies each of its inputs by a number called a weight, adds them all up along with a small adjustment called the bias, and then passes the result through a curve known as an activation function.
The activation function is what stops the network from being a glorified line. Without it, you could collapse a hundred-layer network into a single multiplication. With it, you get the flexibility to model curves, edges, faces, and grammar.
Stacking Neurons Into Layers
One neuron is interesting. A row of neurons working in parallel is a layer. Layers stacked on top of layers form a deep neural network. Each layer learns a slightly more abstract version of the input than the layer before it.
For an image classifier, the first layers tend to detect simple things like edges and colour gradients. Middle layers detect textures and shapes. Late layers detect dogs, faces, signatures, or whatever the network was trained to recognise.
How the Network Actually Learns
At the start, the weights are random. The network is given an example, makes a prediction, and is told how wrong it was. A process called backpropagation works backwards through the network, slightly adjusting every weight in a direction that would have made the prediction less wrong.
Repeat this process millions of times across a large dataset and the weights drift, gradually, into configurations that make sensible predictions on examples the network has never seen.
Common Architectures You Will Hear About
- Feed-forward networks. The simplest case. Information flows in one direction, from input to output.
- Convolutional networks. Specialised for grid-like data such as images. Their weights are organised to detect local patterns regardless of where they appear.
- Recurrent networks. Older sequence models, mostly replaced by transformers but still used in some niches.
- Transformers. The architecture behind almost every modern large language model. Built around the attention mechanism that lets the network selectively focus on relevant parts of the input.
The Math You Actually Need
To genuinely understand what is happening, you need:
- Matrix multiplication, at the level of a first-year linear algebra course.
- The chain rule, at the level of a first-year calculus course.
- A working sense of what gradients and partial derivatives represent.
That is genuinely it. Anything beyond that is helpful for research, not necessary for use.
The Best Way to Build Intuition
Train a tiny neural network from scratch — fewer than 50 lines of Python — on a toy dataset like MNIST. Watching the loss go down and the accuracy go up does more for understanding than reading any book chapter. Andrej Karpathy’s “micrograd” repository is an excellent starting point.
What Comes After
Once the basic mental model is solid, you can branch into specialisations: convolutional networks for vision, transformers for language, graph networks for relational data. Each specialisation is a variation on the same core idea: layered functions, trained by gradient descent.
Follow on Facebook